Kiln is an open-source application security toolset that makes it easy for security teams to find vulnerabilities in their projects and derive insights from the data produced.
You can try Kiln for yourself and contribute to the open source project on GitHub.
Managing security vulnerabilities
Testing for vulnerabilities using CI pipelines
When deploying code, continuous integration (CI) pipelines are typically used to perform tests such as linting, unit testing, UI testing and functional testing. More advanced CI pipelines may also incorporate security tooling to detect security vulnerabilities. At Simply Business, our Ruby application pipelines incorporate bundler-audit, RuboCop and Brakeman for static code analysis and vulnerability scanning.
These tests are useful in highlighting vulnerabilities. However, when a tool does detect an issue, it relies on someone investigating the logs in the failed build to find the reason for a failure. For the developer, it means logging in to the build server and leaving the environment where most of their work is done (e.g. GitHub, code editor). For the security engineer, there isn’t any visibility over whether a security vulnerability has been found.
Data-driven decision making
As security engineers, our customers are not only the external customers of the business but also everyone within the company who works with us. Security teams are frequently small, relative to the number of customers they support. So prioritising where to focus your security team’s efforts becomes ever more important.
One of the ways that security teams can prioritise their efforts is through data-driven decision making. Domains such as business intelligence, marketing and UX are renowned for treating their data as king. As security professionals, we can learn a lot from this.
Here are some of the areas where data can help to inform decision-making for security teams:
- discovering which projects use security tools in their CI pipelines
- finding vulnerable dependencies in production
- knowing which projects present the greatest risks for security
- measuring the impact of security training on application security
We’ll now explore how data generated by Kiln’s open source security tooling can help security teams to answer these questions.

Introducing Kiln
Kiln is an open source application security toolset. Kiln makes it easy to run open source security tooling, and because it also collects data from those tools, this data can be analysed to discover insights about your application security. Kiln is made up of small, self-contained services that can be scaled independently, allowing you to deploy only the services you find useful. Services are written in Rust, packaged in Docker, and are MIT licensed.
Why Kiln?
Kiln provides an easy way to detect security vulnerabilities and generates Slack notifications on the findings to a designated Slack channel. It also helps security teams to determine trends in security issues and the data collected can be used to inform decisions over where to focus the team’s efforts and resources.
Sending security data to a Slack channel
Kiln has a command line interface (CLI) which can be run to scan for dependencies in Ruby applications, using bundler-audit under the hood. Here’s a quick demo on how to run the Kiln CLI (YouTube video) using the open source railsgoat project as an example. The data about any findings are sent as messages to a Slack channel, which can then be monitored by the security team. But where Kiln really comes into its own is when it’s integrated into a CI pipeline.
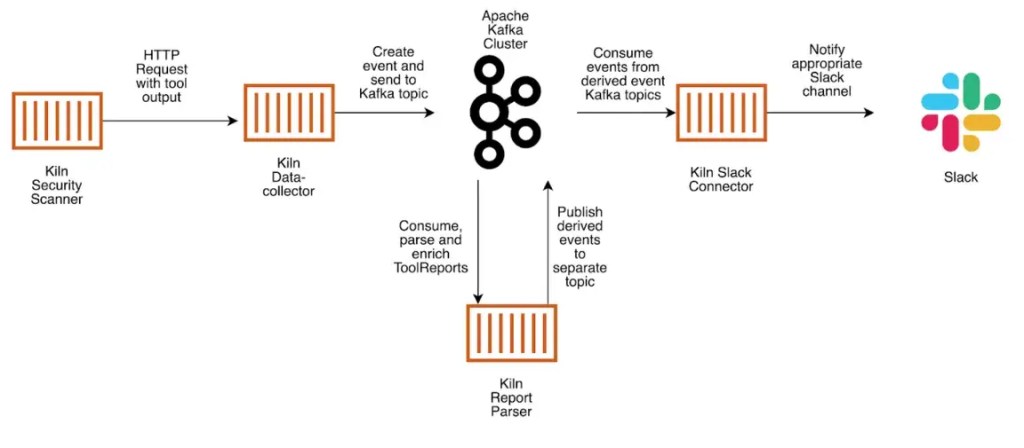
So how does Kiln send bundler-audit output to a Slack channel? Kiln runs through the following steps:
- The Kiln security scanner sends tool output to a data collector, which acts as the validation point and HTTP interface to an Apache Kafka cluster.
- Data is validated and serialised into Apache Avro format, and a message sent to a topic in Kafka.
- The Kiln report parser listens for messages arriving in the ToolReport Kafka topic, parses the messages and performs data enrichment. Reports from each tool are split into separate messages and posted to the DependencyEvents topic.
- If a vulnerable dependency is found, a CVSS score (see National Vulnerability database) is added to the message to indicate the severity.

- The Kiln Slack connector picks up the messages in the DependencyEvents Kafka topic, converts them to text-based messages which are then posted in a designated Slack channel.
Kiln under the hood
Event-driven architecture
Kiln is built on event-driven architecture. Instead of the application state being updated directly, events are recorded that represent changes to the system over time. This makes Apache Kafka a great fit for storing data for Kiln, because Kiln components can replay each event in a topic to build a view of the data.
Kiln’s architecture makes it possible to react to incoming messages quickly, making the whole system very fast. Components are loosely coupled, which enables new components to be plugged in easily. Perhaps one of the main benefits of event sourcing however is that the state of the system can be rebuilt from the events in Kafka, enabling graceful recovery from certain classes of bugs. For example, with event-sourcing, you could make a fix to a calculation performed by an event consumer, deploy a patched consumer and replay events through the patched version to correct an issue.
Scaling and high availability
Kiln uses a Kafka cluster to store messages in topics. Messages are partitioned and replicated across multiple brokers in the cluster so that if a broker node fails, other nodes continue to serve requests until a replacement broker is online. Messages are replicated to the new broker to restore fault-tolerance. Kafka’s consumer groups enable the number of consumers to scale with load, for high availability. In the event that Kiln’s report parsing service is unable to keep up with the number of incoming messages, it’s possible to scale the number of replicas to handle an increased load.
Test-driving Kiln on open source projects
As a test, we used Kiln to explore how long it takes on average to find and fix vulnerabilities in dependencies in these open source projects: OWASP RailsGoat, Mastodon and GitLab. You can view a short video of the Kiln data analysis used in this test on YouTube.
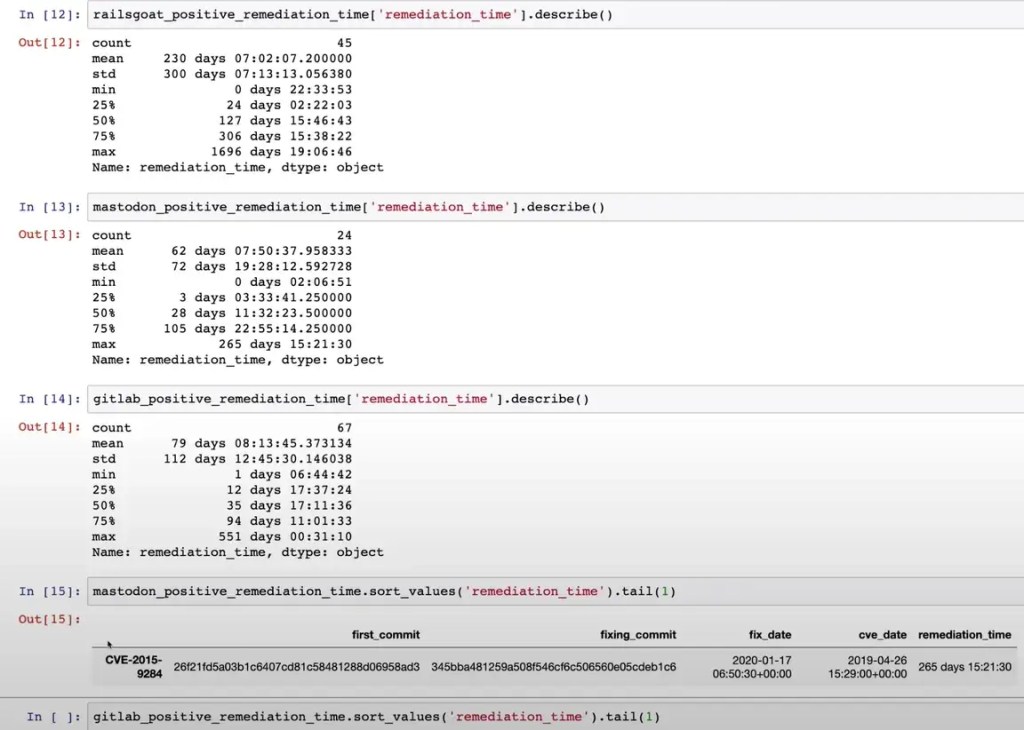
In this test, the Kiln CLI was used to run bundler-audit on every commit to the main branch, and pass the results to a Kiln stack on Amazon Web Services (AWS).
1 – The data was then examined interactively using a Jupyter notebook in Python and Apache Spark Streaming was used to import data from Kafka. Most of the heavy lifting was done using Pandas Python library.
2 – The approach taken in this test was to analyse the data in a batch. Alternatively, you could use streaming to power a live dashboard, and instead of using Jupyter notebooks you could package a Python script to achieve the same results without having to set up Jupyter.
Try out Kiln
If you’re interested in trying out Kiln, you can find the open source code and documentation on GitHub at: Kiln. The Quickstart guide is a good place to start. There is also a practical example of how to analyse data gathered from Kiln to help you explore further.
Kiln is a relatively young project. All of Kiln’s development is tracked using GitHub issues. If you’d like to contribute to Kiln, check out the contributor’s guide.
See our latest technology team opportunities
If you see a position that suits, why not apply today?
We create this content for general information purposes and it should not be taken as advice. Always take professional advice. Read our full disclaimer