A key part of any security management strategy is threat detection, which often incorporates security intelligence tooling such as SIEM (Security Information and Event Management). A SIEM solution can be used to ingest log data from diverse sources across the IT infrastructure, providing the data and analytics to enable security teams to detect and manage threats.
So when integrating SIEM tools into a log management workflow, one of the first considerations is how to pull logs from the various third-party systems. Another major challenge is how to ensure that these logs are being read in their entirety.
Push or pull?
In practice, there are two approaches that can be used to consume logs successfully:
- Relying on the third-party to push logs
- Actively pulling logs from the third-party
The Security team at Simply Business has been investigating the pros and cons of these approaches. From my experience as a Security Engineer, the active pull approach has a slight edge because there is no need to provide third-parties with an open endpoint to which they push data to your organisation.
If we limit our investigation to log-pulling solutions, having a third-party RESTful API to pull from is of major benefit.
A RESTful API is stateless by definition, meaning that all information for each request must come from the client, and no server-side client session is implemented. The server technology will typically offer the option of using pagination tokens that the client can use to store client-side session objects. This implies that clients can use these client-side objects as a way of determining what to read next from the server – something that is paramount for ensuring the completeness of ingested logs.
Implementing a log-pulling framework
We chose to implement a log-reading framework using AWS lambda and DynamoDB, rather than AWS Step Functions or the SOSW framework. Our rationale for doing this will be explained next.
Target solution
Our goal was to implement a solution that could read a full timeline of logs from third-party RESTful APIs that provide support for pagination tokens. We elected to have ‘worker/client’ code being tasked with such reading.
As logs are meaningful only when associated with timestamps, we’re making the following assumptions:
- the third-party APIs support windowing of the log-reading time period, which means that the timeline can be divided into finite-sized windows
- the APIs support pagination.
An example of an API that complies with these conditions is the Google Admin SDK Reports API.
Why do we need orchestration of the log-reading workers?
The simple answer is that it’s not compulsory. However, to enable a worker to determine which time-window of logs to read from the API, it becomes clear that implementing the logic as part of the worker code would greatly increase its complexity.
The workers should really be responsible only for reading the logs. When applying these principles, it seems reasonable to split the codebase and implement the decision-making part of it separately, in an orchestrator function.
General orchestration workflow
We used an orchestrator function as the entry point for executing the orchestration framework. When the orchestrator is executed, it updates the orchestration status and schedules the worker’s execution.
To manage the orchestration status, the orchestrator keeps track of the overall execution by using a timestamp that represents the last moment for which log-reading was scheduled and allocated to a worker. The timestamp must be persisted to a storage solution, and is used by the orchestrator function to progress the log-reading process.
Each worker is scheduled to cover an orchestrator-determined time-window.

Comparing implementation technologies
So far, we’ve drawn a picture of how to make a single orchestration function responsible for deciding how many worker functions to invoke periodically to read logs.
In order to implement such architecture, we’ve considered three different technologies:
- AWS Step Functions
- The Serverless Orchestrator of Serverless Workers (aka SOSW)
- AWS lambda, with the support of AWS DynamoDB
Option 1 – AWS Step Functions
AWS Step Functions offer promising technology for implementing declarative workflows but do not seem to be the right choice for asynchronous invocation of non-idempotent jobs.
Given that a worker’s completion state can be checked by the next execution of the orchestrator, the orchestrator should not be kept running. The call to the worker should in fact be an asynchronous one. Step functions are not thought to support that; each task returns a successful or an unsuccessful completion state.
If we bend this behaviour to always return a ‘promised’ successful completion state and resort to having the worker store the real status on termination, in some form of persistent storage (e.g. AWS dynamoDB rather than S3), we defeat the purpose of having a synchronous coordinating state machine that powers the gears of the workflow and that runs perpetually until the workflow has completed. That’s because the state machine actually reads the status that the workers are persisting as input, at the start of execution.
Step functions are declarative synchronous state machines that power workflows. Their input must be acquired as context for the workflow in the form of CloudWatch event parameters. However, step functions cannot be associated with the triggering of the CloudWatch event. We don’t want the state machine to start every time a worker outputs a state, but rather to execute periodically.
It would be highly inefficient to run a state machine each time the worker’s status is updated, and it may require additional states to skip the execution unless conditions are met.
The way in which step functions support ‘retries’ and ‘catching exceptions’ also does not look fit for our scenario. As stated in the AWS Step Functions documentation, step functions only support the re-execution of idempotent tasks.
A log-reading and transformation operation may be considered an idempotent task. However, since a step function task is run on AWS lambda, it comes with the lambda timeout. What if the sheer amount of logs to read on the worker/task allocated time-window simply exceeds what the worker can cope with before its timeout expires? Can such a worker task be retried as is, in the way that an AWS step function would do?
The answer is no. And this is why even if worker executions can be considered idempotent, our goal to achieve full log-reading completeness cannot be achieved by rescheduling workers as is; they would fail identically.
The event that a worker may not have enough time to read from the API cannot be ruled out, irrespective of the length of time during which the worker is able to read logs or whether the execution timeout is stretched. The time intervals are eventually capped so the only way forward is to design the workflow around these limits.
If an execution does not complete, a new one must be scheduled to cover the same time interval, but shouldn’t merely restart from the beginning of the time-window. If the worker stores the next pagination token each time a page of logs is read, then reading can resume from where it left. This point is the main driver in ruling out using standard AWS tools, such as lambda asynchronous invocation retries and AWS Step Functions.
Option 2 – SOSW
The second framework option we looked at was SOSW.
As it stands, this framework doesn’t seem to uphold the maturity level we’re looking for; the retry mechanism has the same shortfall we encountered with Step Functions. If a worker execution fails, it cannot leave a trace indicating its partial execution. Only a hard ‘success’ or ‘failure’ are possible end states.
The SOSW framework does however come with some nice ideas that are in close alignment with what we would need as part of our solution: a scheduler, an orchestrator, a scavenger, multiple cheap workers, a worker assistant and a form of persisted state – all components of the picture.
Option 3 – the final solution
At last, we have the option of implementing the orchestrator and worker functions as AWS lambda functions. As both the orchestrator and the worker need to persist their status, we also have AWS DynamoDB as the supporting storage layer. DynamoDB can be queried easily and that’s why we’ve made it a preferred solution over S3.
The final flow of execution for the orchestrator ultimately looks like this:
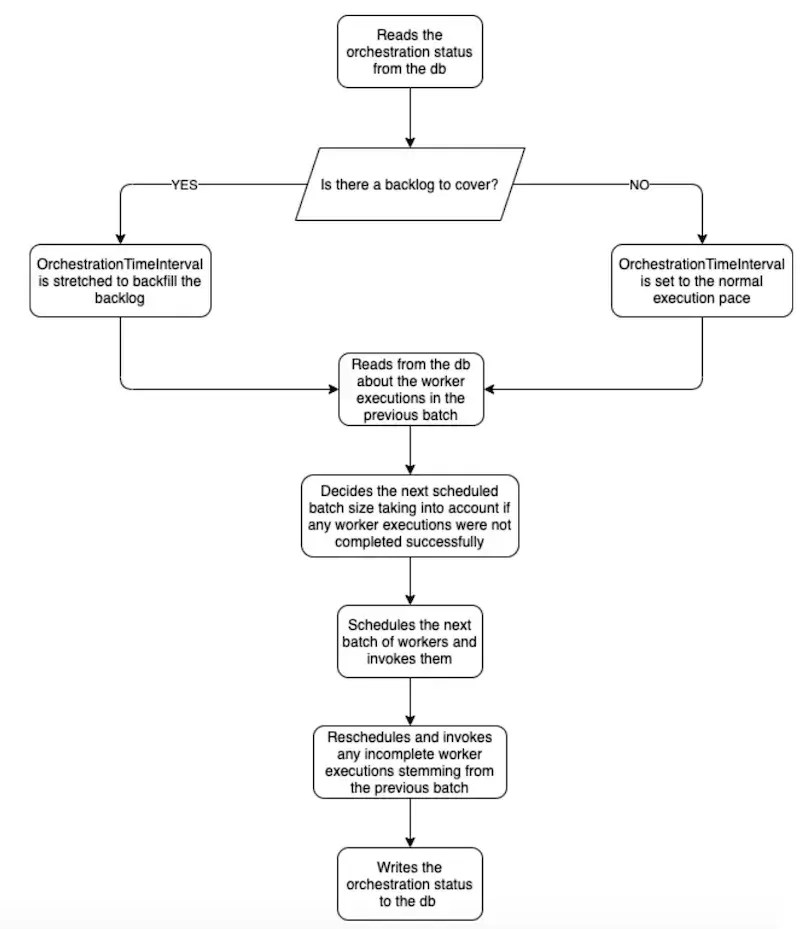
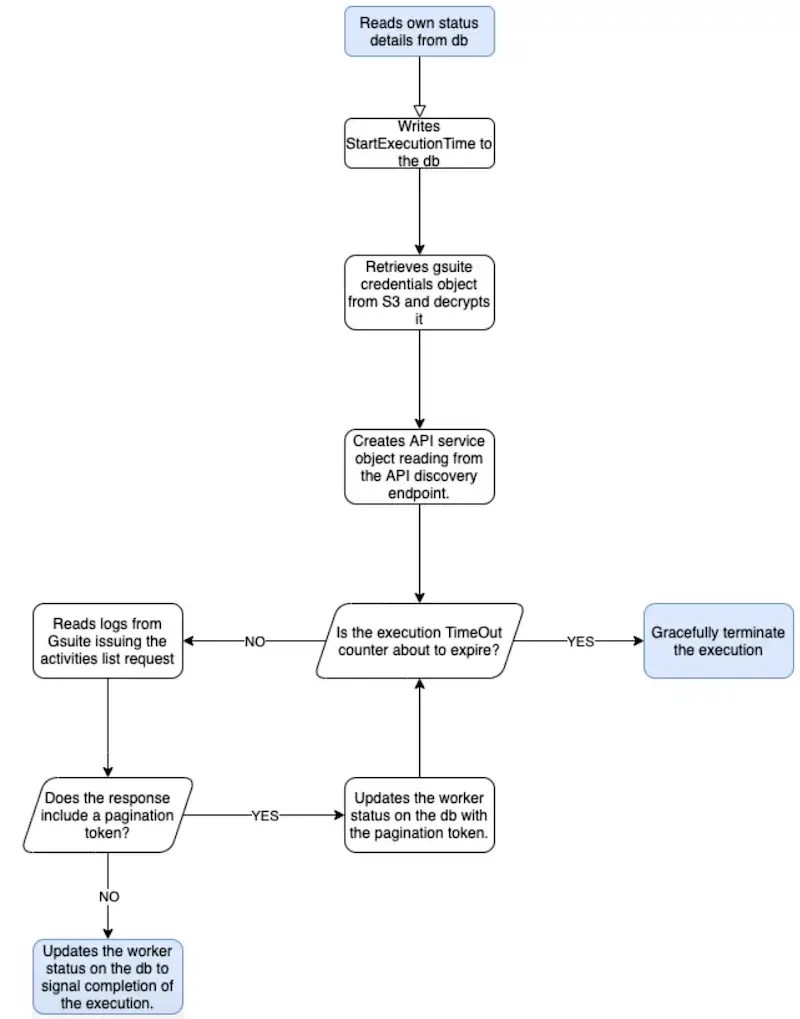
The worker execution flow is implemented as follows:
Conclusion
In this post, we’ve covered how to perform log-reading using third-party APIs that support pagination and windowing, which the majority of RESTful APIs do.
We’ve assessed some mainstream and lesser-known technologies that could have been thought to be used to implement our goal and explained why ultimately, we favoured a custom approach.
Hope you enjoyed the logs-reading techniques discussion!
See our latest technology team opportunities
If you see a position that suits, why not apply today?
We create this content for general information purposes and it should not be taken as advice. Always take professional advice. Read our full disclaimer