We are changing how we architect for scale, versioning, our domain, and machine learning all because of how technology has recently changed.
Why new architecture principles?
Here at Simply Business we’ve long had architecture principles to guide us through the wilds of building our apps. This iteration of the principles is about the future. We have recognized that what an architect needs to consider when architecting a system has changed.
Some of the principles can be fully used today, while others are not fully available yet. I’ll try to point out the status as I explain each principle.
The principles are:
- Web Scale – scaling will no longer be an issue
- Datachain – version and propose everything
- Domain Driven Design – keep your systems aligned with the business model
- Machine learning (ML) is like a database – ML will be an every day tool in software architecture
And for good measure, a long standing principle which still guides us daily:
- Do it right – or don’t do it wrong
Each principle affects how our applications will be architected and developed on the web, and especially impacts how we will build, select partners and develop our technology estate.
So, what do they mean? In this post, I’ll briefly introduce each one. I hope to write more extensive posts for those that require more explanation as and when time permits.
Principle 1: Web Scale
This principle is relatively simple. AWS, Azure, Google Cloud and others provide services where scale is a tuning parameter. The next generation of these services will auto-scale. This means that in the future, the vast majority of system architects will have no need to worry about scaling their creations. It will be as easy to create a web site with 100 monthly visitors as to create one with 100 million monthlies (though the fees to run them will remain very different). In fact, to the architect, they will be exactly the same site.
This also means ‘premature scaling’ won’t be an architectural issue.
A great example of an unlimited scale service (and one that is available today) is Amazon’s S3 service. As long as you put your data in different buckets, there is no limitation whatsoever as to how many reads or writes it can support per second. You pay for what you use, but as an architect, you don’t need to worry if it will scale.
This (effectively) unlimited scalability is turning up all over the place. Serverless functions are the next frontier in unlimited scalability. That being said, today, most serverless solutions have limits, such as rate limits in the case of AWS Lambda. I’m not glossing over these, but more, stating that over time the limits will be removed, and, even now, in many cases cease being architectural design considerations no matter the tuning required.
The most prominent functional area where the future has not arrived, yet, is databases. New database architectures and hosted databases exist that do scale in a relatively unlimited way. However, they require careful tuning and provisioning. Most of them cannot handle a sudden increase in load seamlessly. But still, the revolution is under way. Fauna DB expects to scale seamlessly while Amazon has Dynamo DB on demand pricing, where provisioning capacity is no longer needed.
It won’t be long before we can put an entire ecosystem together without once having to ask “will it scale?”
Principle 2: Datachain, or Version and Propose Everything
Datachain is possibly the most controversial and complicated principle. It takes the amazing power of version control systems such as git and applies that thinking to, well, everything. Instead of storing your transactional data in databases, your data is stored in a system like git, where it is versioned (or a versioned database, not that many of these exist today).
The second bit of version control other than versioning, is branching and merging. In datachain, this is also critical. Users are able to propose a change before making the change. Once the change is approved, that change is stored in the versioned database.
A real world example of this happens daily in Simply Business’s contact centres. We assign our agents to different teams throughout the day, and the phone system needs to know on a real time basis which team each agent is in. We do this so the system can correctly route calls and actions to the correct person. We now use datachain for moving agents across teams.
The steps to assigning an agent to a new team are:
- Create a branch (on Github)
- In the branch, change the team the agent is part of by updating the agent’s record
- Automated tests run on that branch to ensure the change is legit (for example, “does the agent really exist?”)
- The change is approved
- The change is merged to the master branch which triggers a web hook that orders the phone system to change that agent’s team
It is only at step five that the change becomes active. Before that point, the change is a proposed change that is sitting on a branch. By proposing, the change can be vetted and approved over a longer period of time then the span of a single transaction.
Some of the benefits of datachain include:
- Integrated audit trail
- Ability to propose and agree changes in a consistent way
- Ability to see the state of your data at a point in time
- Immutable data
Some of the downsides:
- Enterprise applications, even SaaS, universally don’t support this model
- Even versioned databases (such as Kafka) use timestamps and therefore do not support proposing changes (they don’t support branching)
- It is a new way of thinking about data and therefore tooling and integration methods are immature (to put it mildly)
- This model doesn’t integrate easily with more traditional architectures
- Merging rich data such as images, or Excel spreadsheets is awkward
The initial version of this idea has long been an architectural principle at Simply Business. We call it Github instead of configuration. The idea worked so well, we’ve decided to extend it to our transactional data.
Datachain borrows ideas from, and uses in varying ways: git, event driven application design, event sourcing and Blockchain, the last one probably obvious given the name.
When I have a chance, I will post more detail around this principle (it might even be a whitepaper) and a maturity model so that you don’t have to throw out all your existing applications in order to use it.

Principle 3: Domain Driven Design
Domain Driven Design is a well understood and documented approach to designing software. So rather than belabour that here, I’ll touch on a few personal thoughts on why it’s critical for software architecture. I like to think of the business domain model (whether documented or not) and the software/systems domain model (again whether documented or not) as two separate line segments on a 2D plane. This is not strictly accurate but makes it easy to reason about what happens when change occurs.
The first diagram shows the business domain (how the business runs). When a change to how the business runs occurs, the domain model needs to change to accommodate it. An example would be going from only having individual customers, to serving organizations.
Similarly, the systems domain also needs to be able to change. Here we have the same situation affecting the systems domain.
Here we see what happens when the two domains have the ability to vary but in different directions.
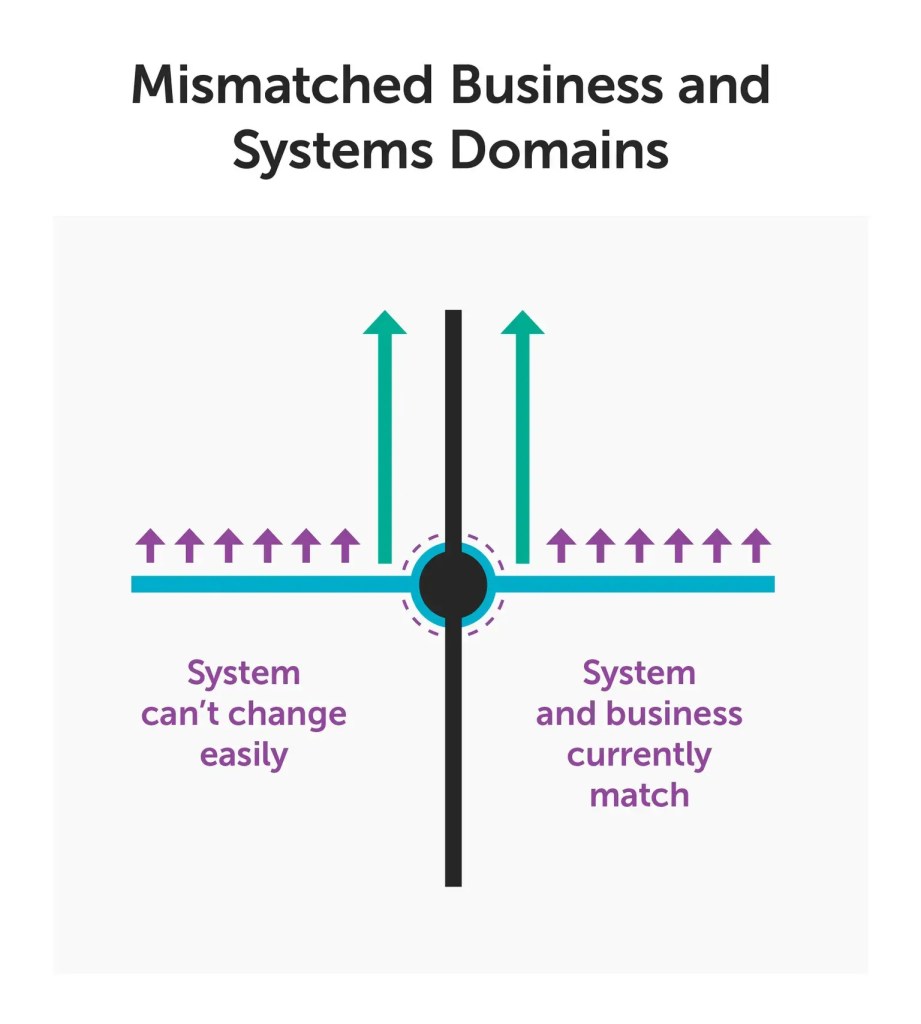
The first thing we notice is that the system supports the current business today, but as soon as the business needs to change, the system can’t easily change alongside it. This then locks the business to the system architecture – never a good look. This happens when the domain model built into the code is different from the actual business domain model. Basically, any change to the business domain model ends up being a hack in the mismatched systems architecture.
When this occurs, changes tend to take much longer than expected. A few possible reasons for this are because a small change in business domain model can lead to sweeping changes in the software, or because the domain model isn’t sufficiently clear so no one quite knows how to make the change, or because the change can only be hacked in to a system that cannot accommodate it.
This next diagram shows what happens when the system and business domain models are the same. Any change to the business model ends up being a similar change to the systems that support it. There is no mismatch and so changes are relatively easy to make. At a minimum, the magnitude of change in both domain models is commensurate.

Principle 4: Machine learning is like a database
This principle is basically borrowed directly from Ben Evens of a16z in his article Ways to think about machine learning. His thesis is that ML will become a tool that underpins every business, just as relational databases did many years ago. Additionally, he states that ML will enable new types of business because certain things that were previously very hard are now easy.
He describes how this effect happened with relational databases. Before relational databases came on the scene, writing a new query was an expensive job requiring many developers and weeks of work. Naturally that led to very few queries being written. When relational databases arrived, and queries could be written in seconds or minutes, whole new classes of business problems could be solved, such as complex reporting. No one knew that that would be the outcome, but eventually these new use cases arose.
Today, we don’t know the full set of classes of problems can be solved with ML that were not feasible before. But, we can easily predict that new classes of solutions will arise.
The challenge remains that it is hard to discern what ML will be good for, leaving it a solution without a problem.
People tend to head in two directions when thinking about ML:
- Over enthusiastic expectations that ML is magic dust that will make everything work better and can solve all problems in sight.
- Thinking that ML has no role to play in the problem they are solving.
Both stem from not understanding what ML can and can’t do, and an overly binary approach to its use.
By adopting this principle we acknowledge that we are searching for applications of ML techniques and that we need to understand the technology well enough so that we can match it to problems and deliver valuable solutions.
Bonus principle: Do it right
“Do it right” has been a principle for a while, and we felt it should be the new old principle. This principle is deceptively simple. All we ask of our people is that when architecting (or doing any other thing), they “do it right.”
People often ask me: “How do I know if I’m doing it right? Where is the manual that tells me how to do it right? What are the rules?”
My answer is always the same: “We hired you as a professional who is good at what you do. If it doesn’t feel right to you, it isn’t. Pay attention to that sick feeling in your stomach. And equally, if you feel really good about what you are doing, then you are probably doing it right. If you just don’t know, ask a colleague for help. And sorry, there is no rule book.”
To sum up
We feel these few principles are excellent for guiding us through the next few years of our growth and architectural evolution. The tech world around us will continue to change dramatically, as it has done in the past. But we’ve picked out a few things we think will come to pass, and will be valuable to us.
Are these the ravings of mad people? Let us know if the comments.
Ready to start your career at Simply Business?
Want to know more about what it’s like to work in tech at Simply Business? Read about our approach to tech, then check out our current vacancies.